Redis 高级客户端 Redisson 简介
Redisson 是什么?
在 Java 生态中,Redisson 是一个非常强大的 Redis 客户端。如果说 Redis 是一台性能卓越的引擎,那么 Redisson 就是一套基于这台引擎开发的 “自动驾驶系统”。它不仅仅是让你操作 Redis 的字符串、哈希等基础数据类型,而是将 Redis 的功能封装成了 Java 原生的集合和工具。比如你想实现一个“分布式锁”,你需要自己写 Lua 脚本、考虑超时、容错等。而在 Redisson 中,你只需要像操作 Java 原生 Lock 一样调用 lock.lock(),复杂的逻辑全由 Redisson 在底层帮你搞定。
在 现代的 Java 领域,Redisson 的地位非常稳固,属于事实上的分布式组件标准。
- 统治地位: 在需要 “分布式锁” 的 Java 场景中,Redisson 的市场占有率几乎是压倒性的。开发者们早已不再流行自己手写 Redis 锁,而是直接引入 Redisson。(Redis 的锁使用的
AP模型,优先保证的是服务的高可用性;如果需要优先保证数据的强一致性,也可以考虑 zookeeper,它是基于CP的实现)。 - 生态融合: 它是很多大型互联网公司(如金融、电商)处理高并发场景的标配。
- 竞品现状:
- Jedis: 属于“老前辈”,虽然简单,但因线程不安全且不支持异步,目前仅在旧项目或极简场景中使用,市场份额持续萎缩。
- Lettuce: 随着 Spring Data Redis 的流行,作为底层驱动的占有率极高,但它与 Redisson 不是替代关系,而是互补关系。
Redisson 与 Lettuce 的对比
两者都是 Java 连接 Redis 的客户端(驱动),但侧重点完全不同。目前在 Spring Boot 生态中,它们经常被 “搭伙” 使用。
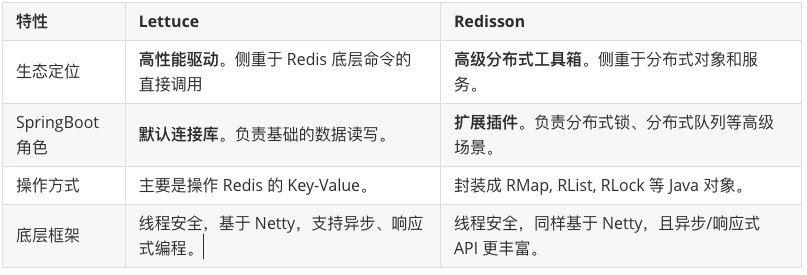
简单来说:
- 如果你只需要快速地读写缓存(Get/Set),Lettuce 性能更好,是 Spring Boot 的首选。
- 如果你需要实现复杂的分布式功能(如:防超卖的分布式锁、延迟队列、生产者消费者模型),Redisson 是不二之选。
更深度比较 :为什么 Redisson 会消耗更多连接?
- 网络与连接效率
- Lettuce (Spring默认):基于 Netty 的连接共享。通常情况下,多个线程可以复用同一个物理连接(通过 Pipeline 机制),极大地节省了 TCP 三次握手的开销,使用 1个长连接就可以承载成千上万个请求。对于常规 CRUD,Lettuce 可能只需要几个连接就能扛住很高的并发。
- Redisson:虽然也基于 Netty,但它更倾向于使用连接池(默认是连接池模式),这意味着在极高并发下,如果连接池设得太小,线程会进入等待状态。为了保证分布式锁、订阅发布等功能的实时性,它会为不同的操作维护独立的连接池。
- 功能性连接占用
- 看门狗与阻塞操作:Redisson 的很多高级功能(如分布式锁、BLPOP 阻塞队列)需要占用独立的连接来维持心跳或阻塞监听。
- Pub/Sub 机制:Redisson 在实现分布式锁时,为了通知其他线程 “锁已释放”,大量使用了 Redis 的 Pub/Sub。而 Redis 的订阅操作是会独占一个连接的。
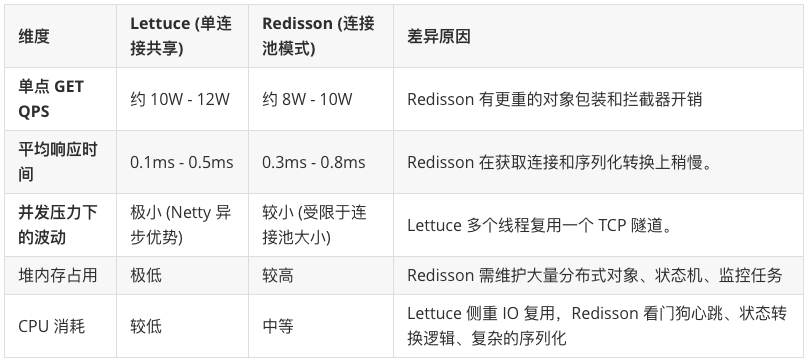
性能参数对比
在纯粹的 GET/SET 操作下,Lettuce 通常略占优势。
Redisson 的开箱即用
虽然我们之前讨论了如何用 Lua 脚本和 ScheduledExecutorService 封装可重入锁和看门狗,但 Redisson 的 RLock 已经处理了更极端的边缘情况:
- 锁的可重入与自动延时:在 redissonClient.getLock(“myLock”) 时,返回的实例就是
RedissonLock。它实现了标准的 java.util.concurrent.locks.Lock 接口,并扩展了 RLock。它支持锁的可重入性,其看门狗(Watchdog)也非常健壮,处理了 Redis 集群切换、单点故障等复杂场景。 - 公平锁与读写锁:Redisson 支持
RReadWriteLock,这在 “高频读、低频写” 的分布式场景下能极大提高吞吐量。 - 信号量与闭锁:如果你需要
分布式环境下的 CountDownLatch 或 Semaphore,Lettuce 封装起来会极其痛苦。
Redisson 封装了复杂的 “全家桶” 功能,以布隆过滤器为例,在 lettuce 中你需要自己去管理位图位操作,或者手动拼 RedisBloom 模块的命令字符串。而对 Redisson 来说:
1 | RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user_filter"); |
如果你想在多个 JVM 之间共享一个 Map,且希望它具备Map 的语义(比如原子性的 putIfAbsent),Redisson 的 RMap 可以像本地 ConcurrentHashMap 一样使用,但数据存储在 Redis 中。
生产环境的建议
具体原则
在生产环境中,我们通常不会用 Redisson 全面取代 Lettuce,而是两者共存:
Spring Data Redis (Lettuce):负责常规的 CRUD 操作(高频的缓存读写、简单的 Key-Value 存储)。它的性能略高,且与 Spring 生态集成最紧密。
Redisson:负责 高阶分布式功能。专门用来处理:
分布式锁
RLock布隆过滤器
RBloomFilter分布式限流器
RRateLimiter消息队列/延迟队列
RDelayedQueue
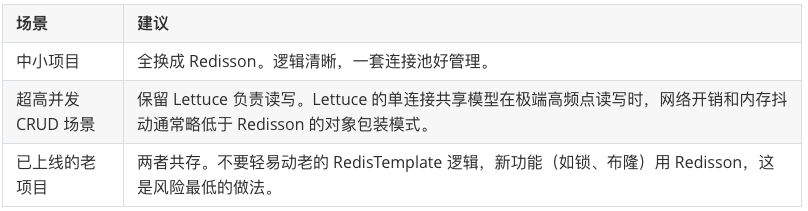
具体项目
对于特定项目,更具体的建议是:
共存需要注意的点
连接数的控制
在现代云环境下,Redis 单机支持上万个连接。如果你的应用节点只有几个,每个节点多出 20-30 个连接,总计不到 200 个,这对于 Redis 来说几乎没有任何性能损耗。真正需要警惕的场景是:你有几百个微服务节点(K8s 伸缩),每个节点都开 64 个连接。 $500 \text{ nodes} \times 64 \text{ conns} = 32,000$。 这会直接撑爆 Redis 的 maxclients。这种情况下,必须严格限制 connectionPoolSize 为 2~4。
在引入 Redisson 后,你应该在生产环境观察 Redis 的 info clients 命令结果:
- connected_clients:当前总连接数。
- maxclients:Redis 服务端允许的最大连接数(通常是 10000)。
如果发现连接数确实增长过快,重点检查是否有 “锁未释放” 或者 “频繁创建/销毁 Redisson 实例” 的情况。
如果你决定 Lettuce 和 Redisson 共存,可以通过以下配置精细化控制 Redisson 的胃口:
① 调小连接池步长:Redisson 默认的连接池配置通常比较慷慨(例如最小 24,最大 64)。对于中小型应用,这太奢侈了。
1
2
3
4
5
6
7
8
9
10# Redisson 配置示例
singleServerConfig:
# 最小空闲连接数(设低一点,比如 8)
connectionMinimumIdleSize: 8
# 最大连接数(根据业务并发量设定,不要用默认的 64)
connectionPoolSize: 32
# 订阅连接池(针对锁的通知,可以设小一点)
subscriptionConnectionPoolSize: 10
# 连接空闲超时
idleConnectionTimeout: 10000② 共享同一个 Client 实例:确保在整个 Spring 上下文中只创建一个
RedissonClient实例。避免在每个 Service 里去 Redisson.create()。③ 区分业务场景:高频小数据读取继续走 Lettuce(它连接利用率极高),分布式锁/复杂集合走 Redisson。这样可以保证大部分请求不占用 Redisson 的连接池。
序列化最好保持一致
在实际中,序列化的一致性直接决定了运维效率和多客户端兼容性。如果 Redisson 和 Lettuce(Spring Data Redis 默认客户端)序列化不一致,你会发现 Redisson 存进去的对象,用 Redis Template 读取出来全是乱码。
Lettuce 默认通常使用 StringRedisSerializer 或 JdkSerializationRedisSerializer。
Redisson 默认使用 Jackson (Smile) 编码。
合理的建议是将所有客户端(Redisson 和 RedisTemplate)统一配置为 JsonJacksonCodec。
- 可读性:运维人员通过 Redis Insight 或命令行工具查看数据时,看到的是明文 JSON,而不是 “\xac\xed\x00\x05” 这种 JDK 乱码。
- 跨平台/跨语言:如果你以后有 Python 或 Go 的脚本需要读写这些数据,JSON 是通用语言,而 JDK 序列化几乎无解。
- 性能平衡:Jackson 的性能和体积在通用场景下表现非常稳健。
在你的 RedissonProperties 和 RedisClusterConfig 中,确保 Codec 被显式指定。
1 | // 在 RedisClusterConfig.java 中 |
为了保持一致,你必须手动配置 RedisTemplate。Spring Boot 默认使用的是 JDK 序列化,我们需要将其 “掰过来”:
1 |
|